There Is No Wall: Progress Towards AGI Continues
Anyone who thinks AI progress will stop is wrong
Some people believe that progress towards AGI will halt because of an imaginary ‘wall’.
These people argue that eventually the big tech companies and AI labs will run into bottlenecks that impede their scaling efforts towards general intelligence, and that the AI ‘bubble’ will burst as a result.
I’m here to tell you there is no wall.
One can debate whether the current technical architecture of these models will get us to AGI (most believe it won’t), but one cannot debate that all the evidence points to progress continuing.
The models continue to get smarter, faster and cheaper.
In case you’ve been living under a rock, the past week of AI developments highlights this.
Let’s dive into everything that’s been released the past few days and how you can take advantage of it.
Gemini 3
During the week Google released their latest AI model: Gemini 3.
For those of you not familiar, ARC-AGI-2 is a test of fluid intelligence (basically, it tests the ability of AI models to solve visual puzzles using general reasoning).
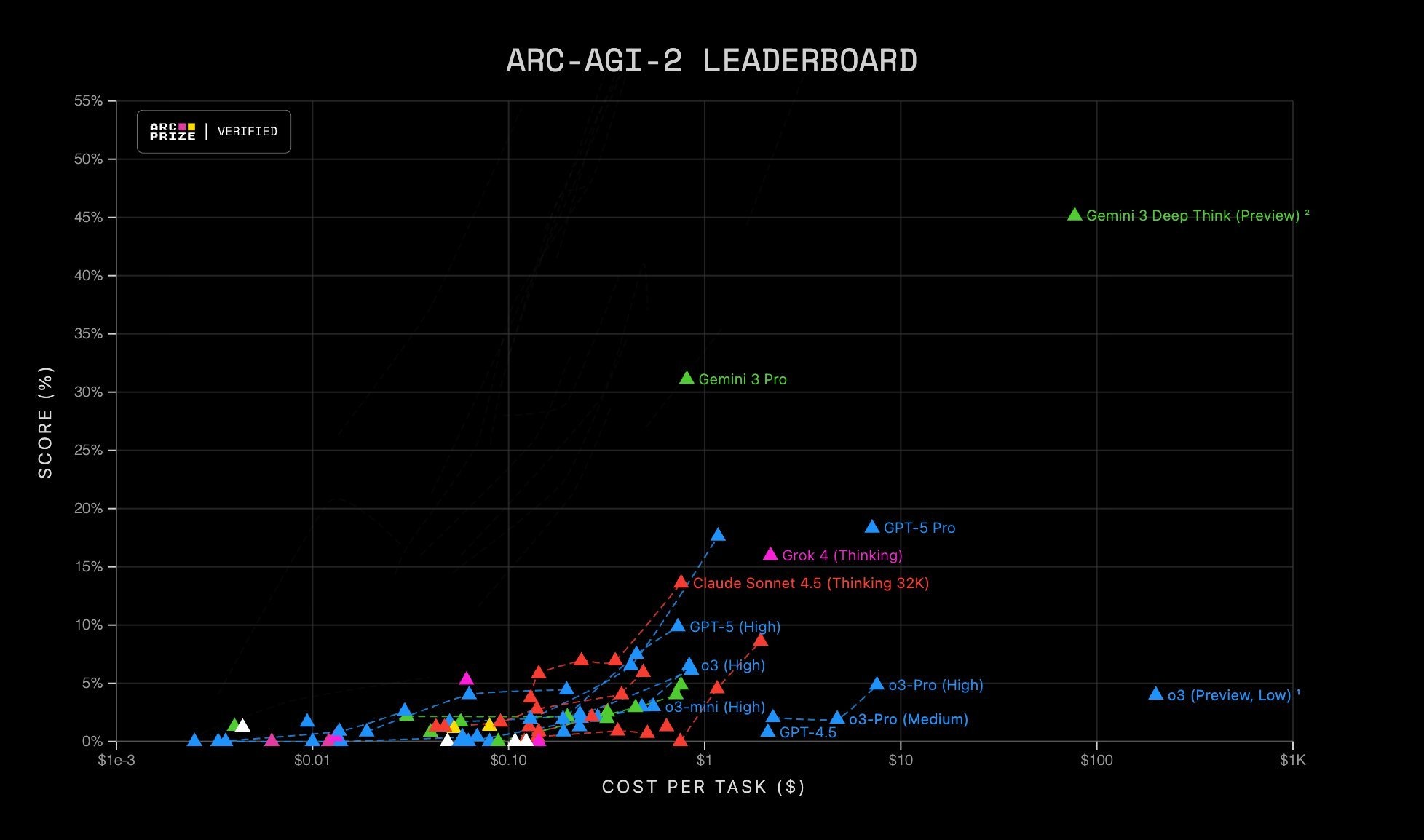
Take a look at the performance of Gemini 3 Deep Think on this test relative to the others - it’s the outlier in the top right.
Head and shoulders above the rest.
So where is the wall?
Let’s take a look at some other benchmarks of Gemini 3.
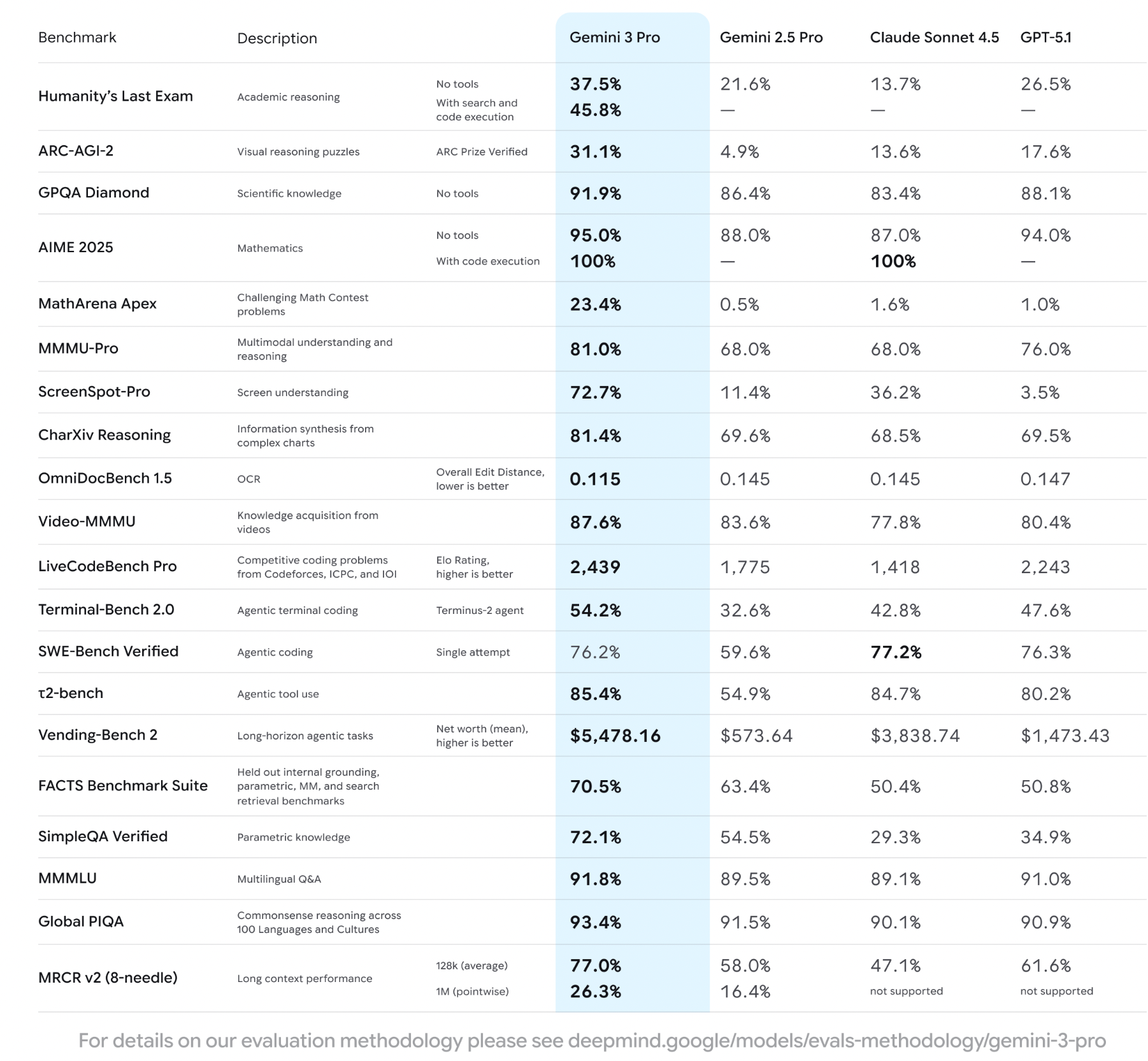
Again, it beats most existing benchmarks compared to GPT 5.1.
Note particularly the score on ScreenSpot-Pro: 72.7% compared to 3.5% for GPT-5.1. i.e. A massive improvement in its ability to understand the visuals on your screen.
This aligns with my own experience using Gemini 3 so far - it is a very powerful model for generating and understanding visual designs, e.g. website landing pages, and is a noticeable step up from previous state of the art models.
GPT-5.1-Codex-Max
Desperate to steal the limelight back from Google, OpenAI fired back with a new release of their own: GPT-5.1-Codex-Max.
It’s a mouthful, but it’s a beast.
For those not familiar, Codex is a model OpenAI trained specifically for software development - many devs now use it every day.
What do the AI researchers think of this model, and how does it compare to Gemini 3?
As AI Researcher Noam Brown states here, this model can work autonomously for more than a day on software development tasks.
Yes, you read that right.
That means OpenAI has tested it internally on tasks where it is capable of receiving a prompt and then performing 24 hours of software work with no human intervention.
The caveat here is we don’t know what the tasks were and what its success rate was for what Noam is claiming.
But it is clear that progress is improving rapidly.

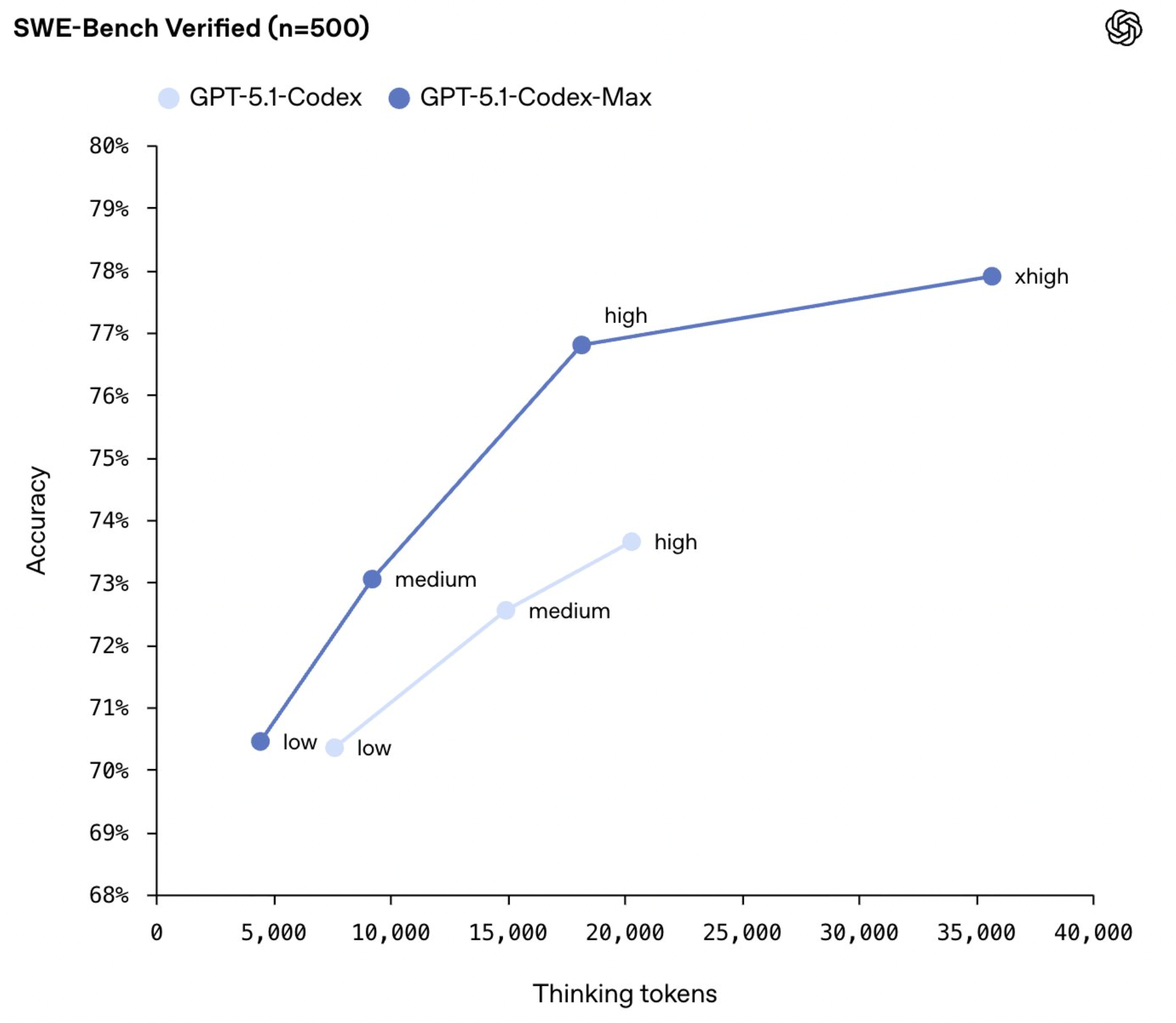
SWE-Bench is a test of a model’s ability to solve real world software engineering tasks.
As you can see above, progress continues to be made with each Codex model iteration.
And perhaps most importantly, as Noam states in his tweet from above, the scaling laws (pre-training and test-time compute) continue to work.
For those not familiar with the scaling laws, the best way to think of it is that giving AI models more capacity, data, and compute during training, and also letting them use more compute at ‘test time’ (when you interact with the model and ask it questions), reliably leads to better performance.
You can read the full model breakdown from OpenAI here.
Here’s one final chart before we dive into how you can take advantage of this knowledge.
This chart reveals the most important insight you must understand about the current progress in AI models:



